【新智元导读】沉寂已久的谷歌GPU神秘面纱终于揭开,在这周召开的体系结构顶会 ISCA 2017 ,描述 TPU 的论文被评为最佳论文,我们也终于得以了解 TPU 的技术细节。在论文中,谷歌将 TPU 的性能和效率与 Haswell CPU 和英伟达 Tesla K80 GPU 做了详尽的比较,从中可以了解 TPU 在推理上性能卓越的原因。
深度学习应用大量涌现使超级计算机的架构逐渐向深度学习应用优化,从传统 CPU 为主 GPU 为辅的英特尔处理器变为 GPU 为主 CPU 为辅的结构。不过,未来相当长一段时间内,计算系统仍将保持 CPU + 协处理器的混合架构。但是,在协处理市场,随着人工智能尤其是机器学习应用大量涌现,芯片厂商纷纷完善产品、推出新品,都想成为智能时代协处理器的领跑者――但问题是,谁会担当这个角色呢?
大约在四年前,谷歌开始注意到深度神经网络在各种服务中的真正潜力,由此产生的计算力需求――硬件需求,也就十分清晰。具体说,CPU 和 GPU 把模型训练好,谷歌需要另外的芯片加速推理(inference),经过这一步,神经网络才能用于产品和服务。
不过,当时的谷歌虽然知道自己需要一种新的硬件架构,但具体的思还不明确。这也正是谷歌当年硬件大牛 Norman Jouppi 挖过去的原因。Jouppi 是 MIPS 处理器的首席架构师之一,开创了很多内存系统中的新技术,提到微处理器设计,Jouppi 的名字几乎无人不知。Jouppi 在接受 The Next Platform 采访时表示,他在三年多以前加入谷歌时手头实际上有好几个选择,但他从来没有想过最终还是走回了 CISC 设备的道。
我们当然在说谷歌的 TPU。这款芯片在去年谷歌 I/O 大会上首次公开亮相,但相关细节一直没有被透露。就在这周召开的体系结构顶会 ISCA 2017 ,描述 TPU 的论文被评为最佳论文,我们也终于得以了解 TPU 的技术细节。在论文中,谷歌将 TPU 的性能和效率与 Haswell CPU 和英伟达 Tesla K80 GPU 做了详尽的比较,从中可以了解 TPU 在推理上性能卓越的原因。
Jouppi 在接受 The Next Platform 采访时表示,谷歌硬件工程团队在决定采用定制 ASIC 的方法之前,在项目初期确实考虑过使用 FPGA 的方案解决廉价、高效和高性能推理的问题。Jouppi 告诉 The Next Platform,使用 FPGA 就是看中了 FPGA 的灵活性,“容易改变/调整”,但是由于可编程性和其他障碍,FPGA 与 ASIC 相比在性能和每瓦性能上还是有很大的差异。Jouppi 解释说:“TPU 跟 CPU 或 GPU 一样是可编程的。TPU 不是专为某一个神经网络模型设计的;TPU 能在多种网络(卷积网络、LSTM模型和大规模全连接的神经网络模型)上执行 CISC 指令。所以,TPU 是可编程的,但 TPU 使用矩阵作原语(primitive)而不是向量或标量。”
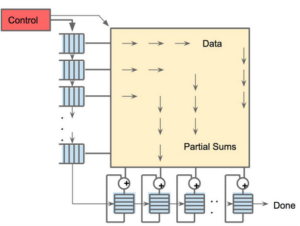
The Next Platform 评论称,TPU 并不复杂,看上去更像是雷达应用的信号处理引擎,而不是标准的 X86 衍生架构。Jouppi说,虽然 TPU 有很多矩阵乘法单元,但 TPU 比“GPU 在思上更接近浮点单元协处理器”,TPU 没有任何存储程序,仅执行从主机发送的指令。
由于要获取大量的权重并将这些权重送到矩阵乘法单元,TPU 上的 DRAM 是作为一个的单元并行运行。同时,矩阵乘法单元通过减少统一缓冲区的读写降低能耗,也就是进行所谓的“脉动运行”(systolic execution)。
TPU 有两个内存,还有一个用于存储模型中参数的外部 DRAM。参数进来以后,从矩阵乘法单元的上层开始加载。同时,可以从左边加载激活,也就是“神经元”的输出。这些都以“systolic”脉动的方式进入矩阵单元,然后进行矩阵相乘,每个周期可以做 64,000 次累积。
鉴于大多数使用机器学习的公司(除了Facebook)都使用 CPU 做推理,因此谷歌 TPU 论文将英特尔“Haswell”Xeon E5 v3 处理器和 TPU 做了对比,而且从数据可以看出,后者在度推理方面性能远超前者。The Next Platform 也由此评论,难怪用惯了 X86 处理器集群做机器学习的谷歌要自己研发一款新的芯片做推理。
相比之下,TPU 使用 8 位整数数算器,拥有 256 GB的主机内存和 32 GB的自身内存,片上内存带宽 34 GB/秒,峰值 92 TOPS,推理吞吐量高了 71 倍,而托管 TPU 的服务器的热功率为 384 瓦。
谷歌还对比测试了 CPU、GPU 和 TPU 处理不同批量(batch)大小的每秒推理吞吐量。
在批量很小、数量为 16 的情况下,Haswell CPU 处理完前 99% 的响应时间接近 7 毫秒,每秒推理数为 5,482 次(IPS),相当于最大值(13,194 IPS,批量 64)的 42%,而达到峰值则用了 21.3 毫秒的时间。相比之下,TPU 可以做到在批量大小为 200 的情况下仍然满足 7 毫秒的上限,并且 IPS 为 225,000 次,达到峰值性能的80%。TPU 在批量大小为 250 的情况下,经过 10 个毫秒就出现了前 99% 的响应。
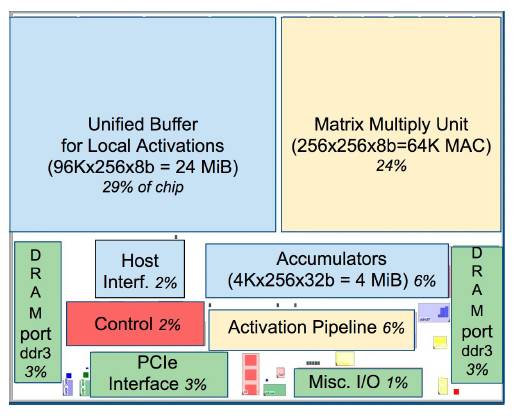
有称,谷歌自己打造芯片,势必对芯片制造商产生巨大影响。确实,面向机器学习专用的处理器是芯片行业的发展趋势,而且未来其他大公司也很有可能组建芯片团队,设计自己专用的芯片。
这后半句话值得商榷。GPU 巨头、英伟达 CEO 黄仁勋日前告诉《华尔街日报》,两年前谷歌就意识到 GPU 更适合训练,而不善于做训练后的分析决策。由此可知,谷歌打造 TPU 的动机只是想要一款更适合做分析决策的芯片。这一点在谷歌的声明里也得到了印证:TPU 只在特定机器学习应用中作辅助使用,公司将继续使用其他厂商制造的 CPU 和 GPU。
需要指出,TPU 是一款推理芯片,因此 TPU 的出现并非是为了取代 GPU――新智元在对英伟达 CEO 黄仁勋的采访中也提到了这一点。TPU 仍然需要结合 GPU 和 CPU 一起使用,本文在一开始也说明了,训练神经网络模型,还是离不开 GPU 和 CPU。而对于 CPU 制造商而言,真正的挑战是提供在考虑到能耗和效率的前提下,具有极高推能的芯片。
3月27日,新智元开源・生态AI技术峰会暨新智元2017创业大赛颁盛典隆重召开,包括“BAT”在内的中国主流 AI 公司、600多名行业精英齐聚,共同为2017中国人工智能的发展画上了浓墨重彩的一笔。
推荐: