问:这代表着“你真棒”,还是代表着“你死定了”?是代表着“礼貌的”,还是代表着“克制的友好”?你是否也曾不禁感叹:这tm到底什么意思……
为了理解一句话背后的情感含义,这些研究人员研发出一套人工智能算法,用来分析:她说的到底是不是反讽?讲真,这套系统比大多数真人更厉害。
深度学习。这些研究人员搭建了一套深度神经网络,然后使用来自Twitter(美国微博)上的大量对话数据进行训练。这个方法之所以可行,还得拜表情符号所赐:人们在微博上表达某种情感时,常常会配上一些表情符号,例如emoji。
这些emoji表情,相当于给那句话,打了一个标签。于是从这个点突破,这套深度学习系统,即便不了解人类高级的反讽技巧,也能通过表情符号发现:事情不妙~
为了训练DeepMoji,研究人员收集了550亿条推文(微博),然后从中选出12亿条带有64种常见emoji表情符号的推文。
首先,他们训练系统来预测哪个表情符号会被用于特定的信息,例如幸福、悲伤、开心对应什么emoji。然后,这套系统被训练用于识别反讽。
这个模型将表情按照负面、正面、爱等不同的情绪进行分类,并且学习不同情绪之间的区别。下面这个图展示了DeepMoji对表情符号的分层聚类。

把语句中的一部分作为嘈杂标签(noisy label)来预训练预测任务不是一个新的想法,但可能之前没人用过一组64个嘈杂标签。需要注意的是,这个项目中嘈杂标签与情感分类的对应关系,并不是通过手动操作完成的,否则可能造成。
研究人员给出的几个基准测试表明,DeepMoji在每种情况下,表现的都比现有最佳算法好得多。也即是说:使用emoji表情符号进行预训练的算法,识别某句话是否反讽的能力有了显著的提升。
除此以外,研究人员还通过Mechanical Turk进行了人类测试。测试结果表明,DeepMoji对一句话中的反讽情绪识别正确率达到82%,而人类平均成绩是76%。
麻省理工还给DeepMoji建了一个官网,有兴趣的同学可以前往围观,地址在:deepmoji.mit.edu。页面上有一个Demo。
当然这个模型也不是没有缺点,例如把“this is the ”认成具有正面情绪,以及“love”这个词的适用范围之广,也让DeepMoji有些困扰。
如下图所示,对于给定的七句话,DeepMoji给出了前五个最有可能对应的emoji表情概率估计。不知道跟你想象的一样么?

这背后是一个严肃的研究,那就是对文本进行复杂情感分析。这个领域的大多数研究,都集中在判断一句话是正面还是负面情绪。但这显然远远不够,无论是实践还是理论都表明,人类的语言中蕴藏着更加复杂和细微的情感表达。
而且随着自然语言处理(NLP)技术的发展,Siri、Alexa等聊器人或者虚拟助理产品,也需要进一步提升对人类语言的理解能力。
这一节,谈谈技术细节。研究人员面临的一个挑战,是如何设计模型和微调方法,才能够让表情符号预训练模型适用于各种新任务。
最后一个LSTM层所学到的特征对于迁移学习任务来说,可能过于复杂了。直接接触网络的上一层可能会更有利于进行迁移。
这个模型可能用于新领域,通过嵌入向量空间给出的特定词语的“理解”会需要更新。然而新领域的数据集可能非常小,因此,简单地用它来训练有2240万参数的整个模型将迅速导致过拟合。
要解决第一个问题,只需要向LSTM模型添加一个简单的注意力机制,它会将之前所有层作为输入,因此在架构中任何层都能轻松访问Softmax层,到先前的任何时间步长。
为了解决第二个问题,研究人员提出了一个“-解冻”微调程序,反复“解冻”网络的某一部分,对其进行训练。这个过程从训练任意新层开始,然后从第一层到最后一层逐层微调,再训练整个模型,如下图所示:

随后附上的论文中展示了这种模型架构确实更适合迁移学习,还说明了使用这样丰富的emoji数据集,比经典的“正面/负面”表情符号区分更好,即使分析的目标只是要区分正负面情绪,也是如此。
在所有基准数据集上,DeepMoji模型的表现都优于现有最高水平,其中所用的“-解冻”方法始终保持了迁移学习的最高性能。
研究中遇到的一个问题,是缺少适当的情绪分析基准数据集,类别最多的情感数据集只有7个情感分类。为解决这个问题,研究人员正在尝试建立一个新的情感基准数据集,希望有助于推动情绪分析研究。

DeepMoji的预处理代码,以及易于使用的预训练模型使用了Keras框架。稍后会全部在GitHub上开源共享。有兴趣的朋友可以记住这个地址:
之所以说易于使用,是因为基于这个模型,只需要几行代码,就可以对一个测试数据集进行预处理,并且对模型进行精细调整。
如果你想扩展词汇表让模型可以涉猎更广,可以进一步调整dropout的比率或其他方法。稍后放出的代码里会有详细的说明。
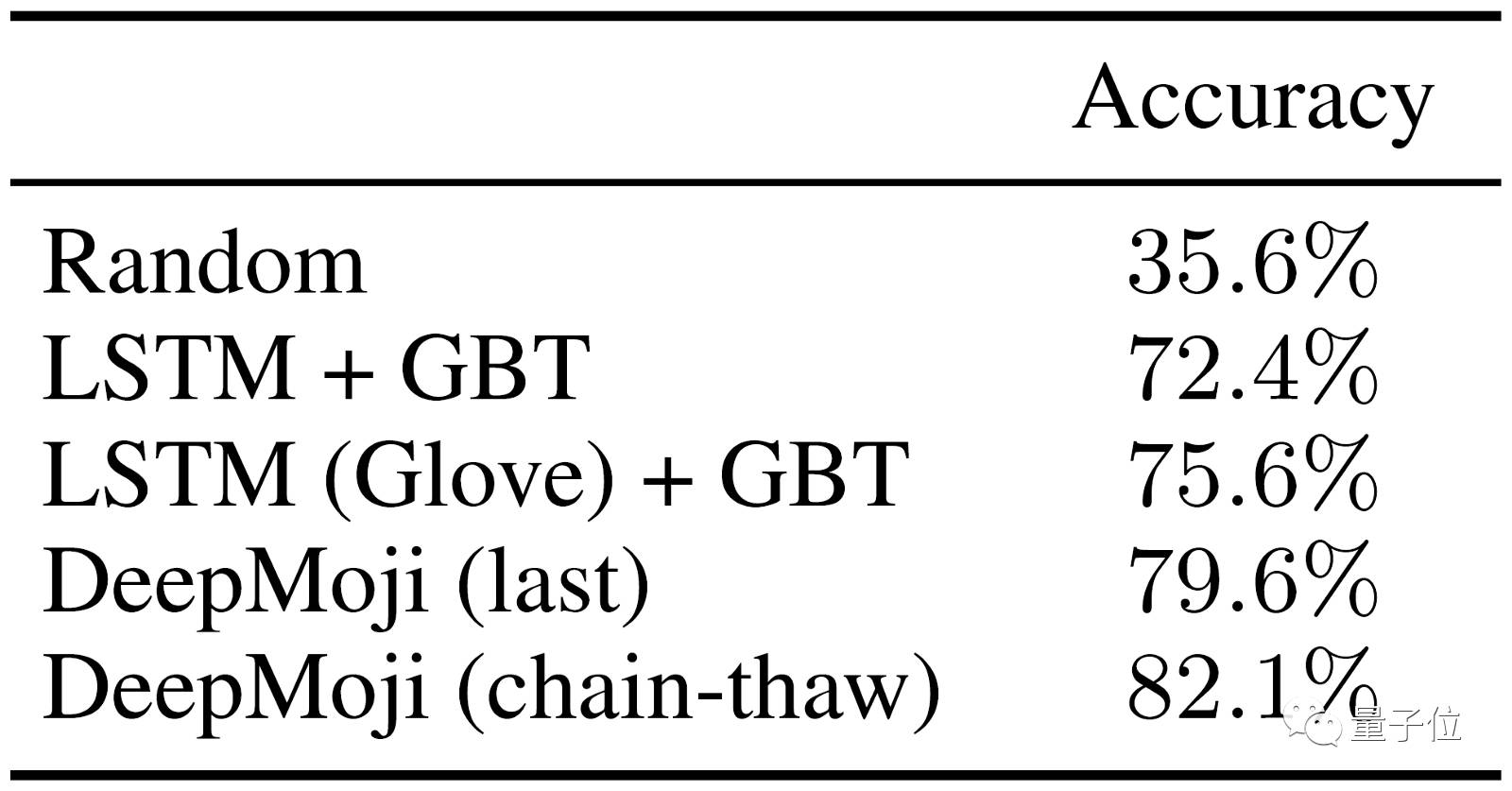
这里还有DeepMoji与目前最先进方法的比较,这个方法结合了LSTM模型+梯度增强树(GBT)分类器。DeepMoji获得了82.1%的准确率,而对照组最好的成绩是75.6%。有趣的是,“-解冻”方法有助于提高准确率。
NLP任务常常受限于手动注释数据的稀缺。因此,在社交情绪分析和相关任务中,二元化表情符号和特定主题标签已经成为研究人员使用的远程监督(distant supervision)形式。我们的研究表明,通过将远程监督扩展到更多样化的嘈杂标签,模型可以学习更丰富的表示。 通过对12.46亿条包含64个常见emoji的twitter进行分析,预测它们所对应的emoji,我们使用单一预训练模型,在情绪、情感和检测的8个基准数据集上取得了最高水准的表现。分析,我们所用的情感标签的多样性,与以往的远程监督方法相比,带来了性能的改进。
推荐: